
Machine Learning o Aprendizaje Automático: hay quienes dicen que es más importante que el fuego o la electricidad o que va a quitarnos nuestro trabajo. Es una tecnología tan importante que ha sido usada por científicos, periodistas, emprendedores, y por supuesto, ingenieros.
Más allá de creernos o no el hype actual, el Machine Learning es una herramienta poderosa y la demanda de gente con habilidades para aplicarlo no hace más que crecer. Además, con semejantes declaraciones rondando, ¿quién querría quedarse rezagado?
Si disfrutas de lanzarte al agua cuando quieres aprender algo nuevo, sigue leyendo porque vamos a escribir un programa que usará Machine Learning para detectar correos spam en sólo 40 líneas de código.
Prediciendo el futuro una línea de código a la vez
Cuando se trata de hacer predicciones, los datos guardan el secreto para ver el futuro. La llave para descubrirlo está en las técnicas de Machine Learning.
Por eso vale recalcar que Machine Learning es un conjunto de técnicas, una fusión de disciplinas, y siempre involucra datos. Nuestras predicciones serán tan precisas como los datos lo permitan. Por ejemplo, Facebook, es tan acertado al mostrar publicidad (al punto de parecer que escucha nuestras conversaciones) porque además de sus modelos predictivos tiene una enorme cantidad de información que nosotros le entregamos todos los días.
¿Qué es Machine Learning?
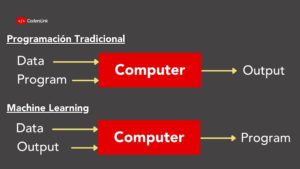
Una explicación simple es la siguiente: si en programación tradicional el programador escribe explícitamente las instrucciones para resolver un problema; en Machine Learning, el programa aprende dichas instrucciones por sí mismo. El programador se preocupa de crear un modelo y supervisar su entrenamiento.
Machine Learning vs. Inteligencia Artificial vs. Deep Learning
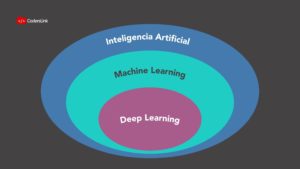
Antes de comenzar, aclaremos la diferencia entre estos 3 términos que se suelen usar intercambiablemente. Pese a estar relacionados, no quieren decir lo mismo:
Deep Learning es el método de machine learning en el que se usan redes neuronales de múltiples capas.
Machine learning son las técnicas para hacer que una máquina aprenda a hacer tareas sin programación explícita.
Inteligencia artificial<span style=”font-weight: 400;”> es el estudio de la inteligencia llevada a cabo por máquinas. Incluye robots, inteligencia artificial generada (AGI), etc.
Tutorial para crear un detector de spam con Machine Learning
Un detector de spam es una aplicación de Machine Learning muy popular. La problemática es simple: crear un programa que determine si un email es spam o no basado en su contenido.
Para ello usaremos regresión logística: un modelo de análisis que permite categorizar un elemento según su probabilidad de tener valores discretos: blanco/negro, victoria/derrota, spam/no spam, etc.
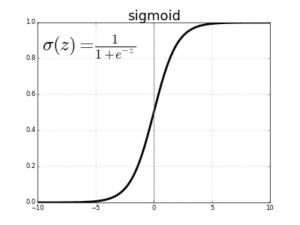
La regresión logística usa una función llamada sigmoide para modelar una variable binaria y(¿es o no spam?) que depende de valores independientes donde r es el número de inputs o predictores (en este caso r=1: el contenido del mail).
Empezaremos con valores conocidos de x y y, que son los datos de entrenamiento. Y separaremos una parte de nuestros datos para evaluar qué tan preciso es el modelo; estos son los datos de prueba.
Nuestra meta es encontrar la función de regresión logística p(x) tal que las predicciones p(x) sean tan cercanas como sea posible a la respuesta real yi por cada observación i=1,…,n.
Una vez tengamos la función p(x), podremos usarla para predecir observaciones nuevas.
¡Manos a la obra!
Usaremos Google Colab, un servicio en la nube basado en Jupyter para crear cuadernos con código y texto. También vamos a descargar el dataset de emails spam de Kaggle. Así no hay que configurar nada en nuestra propia máquina.
Aquí puedes encontrar el ejercicio resuelto.
Colab permite usar R y Python. Como buenos piratas, elegimos Python (yargh!), usando algunas librerías que vienen instaladas:
- Pandas.- Provee la estructura DataFrame para manipular tablas numéricas.
- Numpy.- Añade soporte para operar con matrices multidimensionales.
- scikit-learn.- Incluye varios algoritmos de Machine Learning (incluyendo regresión logística). Nos servirá para abstraernos de detalles que no nos interesa cubrir en este tutorial.
Una vez en Colab, creamos un nuevo cuaderno y las primeras líneas son para subir el archivo csv que contiene los emails.
from google.colab import files
uploaded = files.upload()
Una vez seleccionado y subido el archivo, permanecerá en memoria para su uso.
spam_data = pd.read_csv(io.BytesIO(uploaded['spam_ham_dataset.csv']))
spam_data.head()
La función head imprime los primeros valores que contiene un DataFrame.
Pre-procesamiento de datos
Antes de entrenar el algoritmo, seleccionamos solamente las columnas que nos sirven, lo cual ahorra tiempo y memoria.
new_data = spam_data[['text', 'label_num']].copy()
new_data.rename(columns={'label_num': 'is_spam'}, inplace=True)
def preprocess(text):
text = text.translate(str.maketrans('', '', string.punctuation))
text = [word for word in text.split() if word.lower() not in stopwords.words('english')]
return " ".join(text)
p_text = new_data['text'].copy()
p_text = p_text.apply(preprocess)
p_text
Así se ven ahora los campos text:

Vectorizar los datos, es decir recoger cada palabra de cada text y su frecuencia de aparición. Esto retorna una matriz. Luego la separamos en datos de entrenamiento y prueba.
vectorizer = TfidfVectorizer('english')
message_matrix = vectorizer.fit_transform(p_text)
text_train, text_test, is_spam_train, is_spam_test = train_test_split(
message_matrix, new_data['is_spam'], test_size=0.3, random_state=42
)
Entrenando y evaluando
Aquí es donde sucede la magia. Con el modelo que elegimos previamente (LogisticRegression) y los datos de entrenamiento, llamamos a la función fit. Finalmente evaluamos su precisión usando los datos de prueba, obteniendo alrededor del 98% ????.
model = LogisticRegression(solver='liblinear', penalty='l2')
model.fit(text_train, is_spam_train)
prediction = model.predict(text_test)
accuracy_score(is_spam_test, prediction)
![]()
¿Qué sigue ahora?
Si intentas probar tu modelo con algún mensaje “real” notarás que su capacidad predictiva no es muy buena, además de funcionar sólo con texto en inglés.
Si quieres explorar un poco más, trata de extraer los datos de tus correos y entrena al algoritmo con ellos.
Con este ejercicio hemos arañado la superficie. Si te quedaste con curiosidad, te recomiendo ver FastAi, que está hecho en Python y usa las mismas librerías vistas en este tutorial.

Vacantes Recientes
Blogs Relacionados






